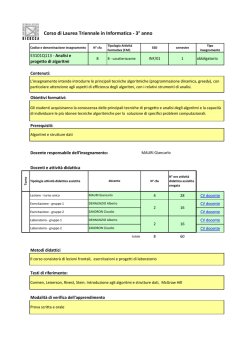
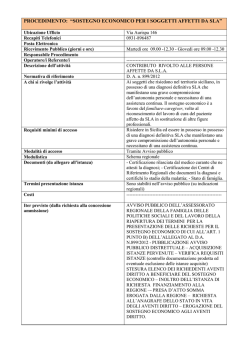
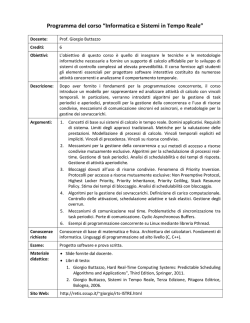
Algoritmi Euristici
Corso di Laurea in Informatica e Corso di Laurea in Matematica
Roberto Cordone
DI - Universit`a degli Studi di Milano
Lezioni:
Mercoled`ı 08.30 - 10.30
Ricevimento:
su appuntamento
Tel.:
02 503 16235
E-mail:
roberto.cordone@unimi.it
Web page:
http://homes.di.unimi.it/~cordone/courses/2014-ae/2014-ae.html
Venerd`ı 08.30 - 10.30
Lezione 5: Analisi sperimentale di prestazione
Milano, A.A. 2014/15
1 / 28
Efficacia di un algoritmo euristico
L’efficacia di un algoritmo euristico pu`
o essere sottoposta ad
• analisi teorica (a priori): dimostrare che l’algoritmo fornisce soluzioni
con una data garanzia di qualit`a sempre o con una data frequenza
• analisi sperimentale (a posteriori): misurare le prestazioni
dell’algoritmo su un campione di istanze di benchmark
L’analisi teorica `e complicata dal fatto che
• spesso l’impatto di un’operazione sulla soluzione non `
e diretto, ma
deriva da interazioni con altre operazioni
• se vi sono passi casuali, si richiede un trattamento statistico anche
usando il criterio del caso pessimo
Le conclusioni dell’analisi teorica possono essere insoddisfacenti in pratica
perch´e fondate su assunzioni poco rappresentative
• un caso pessimo infrequente
• una distribuzione di probabilit`
a delle istanze irrealistica
This material is partly based on slides provided with the book “Stochastic Local Search” by H. H.
Hoos und T. St¨
utzle, (Morgan Kaufmann, 2004) - see www.sls-book.net for further information.
2 / 28
Analisi sperimentale
L’approccio sperimentale `e molto comune nella scienza
• la matematica `
e un’eccezione, fondata sull’approccio formale
• ma l’algoritmica `
e un’eccezione nell’eccezione
Perci`
o si tende a dimenticare le basi del metodo sperimentale scientifico
1
partire dall’osservazione
2
formulare un modello (ipotesi di lavoro)
finch´e non si ottiene un modello soddisfacente
3
a)
b)
c)
d)
progettare esperimenti computazionali per validare il modello
condurre gli esperimenti e raccoglierne i risultati
analizzare i risultati con metodi quantitativi
rivedere il modello in base ai risultati
Che cosa si intende con “modello” nello studio degli algoritmi?
3 / 28
Obiettivi dell’analisi
L’analisi sperimentale indaga
• in fisica le leggi che regolano il comportamento dei fenomeni
• in algoritmica le leggi che regolano il comportamento degli algoritmi
Si tratta di
1
ottenere indici sintetici di efficacia e di efficienza di un algoritmo
2
confrontare l’efficacia di algoritmi diversi per indicare il migliore
3
descrivere il legame fra efficacia o efficienza di un algoritmo e
parametri delle istanze (dimensione n, ecc. . . )
4
suggerire miglioramenti all’algoritmo
4 / 28
Benchmark
Non potendo testare tutte le istanze, occorre definire un campione
Un campione significativo deve coprire diverse
• dimensioni, in particolare per l’analisi sperimentale della complessit`
a
• caratteristiche strutturali (per i grafi: densit`
a, grado, diametro, . . . )
• tipologie
• di applicazione: logistica, telecomunicazioni, produzione, . . .
• di generazione: realistiche, artificiali, trasformazioni di altri problemi
• di distribuzione probabilistica: uniforme, normale, esponenziale, . . .
Non ha senso cercare un campione strettamente “equiprobabile” perch´e
• si devono evitare le istanze che richiedono troppo tempo
• bisogna raccogliere dati in quantit`
a sufficiente a fare estrapolazioni
• ci si deve concentrare sulle istanze pi`
u difficili
• avranno un impatto pi`
u forte (anche ipotizzando l’equiprobabilit`
a)
• sono quelle da cui si pu`
o imparare di pi`
u
• ci si deve concentrare sulle istanze pi`
u frequenti in pratica
• avranno un’utilit`
a maggiore per le applicazioni
5 / 28
Riproducibilit`a
Il metodo scientifico richiede risultati riproducibili e controllabili
• per quanto riguarda le istanze, occorre usare
• istanze gi`
a pubblicamente disponibili
• nuove istanze rese disponibili
• per quanto riguarda l’algoritmo, occorre specificare
• esattamente e completamente i dettagli implementativi
• il linguaggio di programmazione
• il compilatore
• per quanto riguarda l’ambiente, occorre specificare
•
•
•
•
la macchina usata
il sistema operativo
la memoria disponibile
...
La riproduzione di risultati ottenuti da altri `e estremamente difficile
6 / 28
Analisi della qualit`a della soluzione
Consideriamo l’esecuzione dell’algoritmo A come un esperimento casuale
• l’insieme delle istanze I costituisce lo spazio degli esiti
• la differenza relativa δA (I ) `
e la variabile aleatoria sotto indagine
Le prestazioni di A sono descritte dalle propriet`a statistiche di δA (I )
• i parametri di uso pi`
u comune e classico
• il valore atteso di δA (I )
• la varianza di δA (I )
tendono a “subire” l’influsso dei valori estremi (specie quelli cattivi)
• di recente, si cominciano a preferire altre statistiche descrittive
• pi`
u dettagliate
• pi`
u “stabili”
7 / 28
Solution Quality Distribution (SQD)
La descrizione completa si ottiene con la funzione di distribuzione, che
indica la probabilit`a che δA (I ) ≤ α per ogni α ∈ R
La funzione di distribuzione di δA (I ) fornisce il diagramma SQD
8 / 28
Solution Quality Distribution (SQD)
Per qualsiasi algoritmo, la funzione di distribuzione di δA (I )
• `
e nulla per α < 0
• tende a 1 per α → +∞
• `
e costante a tratti (I `e un insieme discreto)
• `
e monotona non decrescente
Inoltre, se si considerano
• algoritmi esatti, `
e una funzione a gradino, pari a 1 per ogni α ≥ 0
• algoritmi α
¯ -approssimati, `e una funzione pari a 1 per ogni α ≥ α
¯
9 / 28
Protocollo per generare il diagramma SQD
In pratica, si ricostruisce un diagramma campionario della funzione
1 Si genera un campione B ⊂ I di istanze indipendenti
(con |B| = k sufficientemente grande)
2 Si applica l’algoritmo a ogni istanza I ∈ B e si costruisce l’insieme
∆A,B = {δA (I ) : I ∈ B}
3
4
Si ordina ∆A,B per valori non decrescenti:
∆A,B = {δ1 , . . . , δk }
j
Si riportano nel grafico i punti δj ,
per j = 1, . . . , k
k
10 / 28
Diagrammi SQD parametrici
Dati i problemi teorici e pratici nella definizione di un campione
significativo spesso il diagramma `e parametrizzato rispetto a
• un parametro strutturale delle istanze (dimensione n, . . . )
• un parametro probabilistico della distribuzione assunta per le istanze
Questo rende pi`
u limitate le conclusioni, ma pi`
u significativo il campione
Inoltre, permette di individuare delle tendenze generali
11 / 28
Statistiche descrittive e boxplot
Una rappresentazione pi`
u compatta `e data da statistiche descrittive come
• il valore atteso e la varianza campionarie
(pi`
u classici)
• la mediana e i vari quantili campionari
(pi`
u “stabili”)
• il diagramma box-plot (o box and whiskers plot), che riporta
• mediana campionaria (q0.5 )
• quartile inferiore e superiore campionari (q0.25 e q0.75 )
• valori estremi campionari (spesso indicando a parte gli “outlier”)
12 / 28
Confronto fra algoritmi con i diagrammi SQD
Come si fa a dire che un algoritmo `e meglio di un altro?
• dominanza stretta: ottiene risultati migliori su tutte le istanze
δA2 (I ) ≤ δA1 (I )
per ogni I ∈ I
Di solito, avviene solo in casi banali (per es., A2 “contiene” A1 )
• dominanza probabilistica: la funzione di distribuzione ha valori pi`
u
alti per ogni valore di α
FA2 (α) ≥ FA2 (α)
per ogni α ∈ R
Esempio: l’algoritmo ILS trova con alta probabilit`a differenze minori di
MMAS, ma anche maggiori. Non c’`e dominanza: ILS `e meno “robusto”
13 / 28
Confronto fra algoritmi con i diagrammi boxplot
Un confronto pi`
u sintetico si pu`
o condurre con i diagrammi boxplot
Se i diagrammi sono completamente separati, c’`e dominanza stretta
La dominanza probabilistica si pu`
o intuire dalla posizione relativa dei
cinque quartili disponibili (q0 , q0.25 , q0.5 , q0.75 , q1 )
14 / 28
Test statistici
I diagrammi sono per`
o sempre empirici: come sapere se la differenza
empirica fra due algoritmi dati, A1 e A2 , `e significativa?
(A )
(A )
Per semplicit`a studiamo le mediane q0.51 e q0.52 , ignorando la robustezza
(per confrontare intere distribuzioni c’`e il test di Kolmogorov-Smirnov)
Le variabili aleatorie δA1 (I ) e δA2 (I ) son definite sullo spazio degli esiti I
• si formula l’ipotesi nulla H0 : le due distribuzioni hanno la stessa
mediana teorica
• si sceglie un livello di significativ`
a α, che sar`a la probabilit`a massima
• di rifiutare H0 nell’ipotesi che sia vera,
• cio`
e di considerare diverse due mediane che invece sono identiche
• cio`
e di considerare diversamente efficaci due algoritmi equivalenti
(a livello di mediana dell’errore)
Valori tipici sono α = 5% o α = 1%
• si estrae un campione di istanze B e gli si applicano i due algoritmi
• si applica alle coppie di valori ottenuti il test di Wilcoxon, ottenendo
una probabilit`a p che indica quant’`e probabile la relazione fra le
coppie di valori osservati, supponendo vera H0
• se p < α, si rifiuta H0
15 / 28
Test di Wilcoxon (ipotesi)
` un test non parametrico, cio`e non fa ipotesi sulla distribuzione di
E
probabilit`a dei valori testati
Questo lo rende adatto a valutare algoritmi euristici, dato che la
distribuzione della differenza relativa δ (I ) per tali algoritmi non `e nota
Si basa sulle seguenti ipotesi:
• i dati sono accoppiati e vengono dalla stessa popolazione
(si ottengono applicando A1 e A2 alle stesse istanze, estratte da I)
• ogni coppia di dati `
e estratta indipendentemente dalle altre
(le istanze vengono generate in maniera fra loro indipendente)
• i dati sono misurati su scale almeno ordinali
(non contano i valori ottenuti, ma il loro ordine relativo)
16 / 28
Test di Wilcoxon (esecuzione)
Il test esegue le seguenti operazioni
1
calcola le differenze assolute |δA1 (I ) − δA2 (I )| per i = 1, . . . , k
2
le ordina per valori crescenti e attribuisce un rango Ri a ciascuna
3
somma separatamente i ranghi delle coppie con differenza positiva e
quelli delle coppie con differenza negativa
+
W =
−
W =
P
Ri
i:δA1 (Ii )>δA2 (Ii )
P
Ri
i:δA1 (Ii )<δA2 (Ii )
Se l’ipotesi nulla H0 fosse vera, le due somme dovrebbero coincidere
4
5
la differenza fra W + e W − consente di calcolare il valore di p
(i 2k esiti indicano se la prima, seconda. . . differenza `e positiva o no:
si conta quanti hanno |W + − W − | pari o superiore all’osservazione)
se p < α, la differenza `e significativa
• se W + < W − , A1 `
e meglio di A2
• se W + > W − , A1 `
e peggio di A2
17 / 28
Conclusioni possibili
Il test di Wilcoxon pu`
o suggerire
• che uno dei due algoritmi sia significativamente migliore dell’altro
• che i due algoritmi siano statisticamente equivalenti
Se il campione `e composto da classi di istanze parametricamente distinte,
algoritmi complessivamente equivalenti potrebbero non esserlo sulle
singole classi di istanze; lo studio rivelerebbe
• classi di istanze a cui conviene applicare A1
• classi di istanze a cui conviene applicare A2
• classi di istanze sulle quali i due algoritmi si equivalgono
18 / 28
E il tempo?
Il confronto di algoritmi che richiedono tempi diversi `e in generale iniquo
(a meno che risparmiare tempo non sia esplicitamente definito inutile)
Un algoritmo `e migliore di un altro quando contemporaneamente
1
ottiene risultati migliori
2
richiede un tempo inferiore
Analisi che prescindono dal tempo di calcolo possono valere se
• si considera un algoritmo singolo senza fare confronti
• si confrontano varianti di un algoritmo che richiedono ugual tempo
di calcolo (tipicamente, ottenute variando un parametro numerico)
• si confrontano algoritmi che hanno molte operazioni in comune e
differiscono solo per operazioni di durata relativamente trascurabile
19 / 28
Analisi del tempo di calcolo (diagramma RTD)
Anche T (I ) si pu`
o descrivere come variabile aleatoria in In : la funzione
di distribuzione fornisce il diagramma Run Time Distribution (RTD)
Diagrammi significativi si ottengono solo tenendo fissa la dimensione n
(e altri parametri rilevanti suggeriti dall’analisi del caso pessimo)
Se tutti i parametri influenti sono stati individuati, il diagramma RTD
degenera in un diagramma a gradino, con valore di soglia E [T (I ) |I ∈ In ]
20 / 28
Analisi del tempo di calcolo (diagrammi di scaling)
L’andamento del tempo medio di calcolo al variare di n pu`o comunque
essere significativamente inferiore alla stima nel caso pessimo
Uno studio sull’andamento empirico del tempo di calcolo richiede di
• estrarre una sequenza di campioni Bn per valori crescenti di n
• applicare l’algoritmo e calcolare i valori medi di T (I ) per ogni n
P
T (I )
I ∈Bn
• tracciare i punti n,
|Bn |
• ipotizzare un’interpolante con l’aiuto dell’analisi teorica
• tarare i parametri dell’interpolante
21 / 28
Relazione fra qualit`a e tempo di calcolo
` in generale scorretto confrontare
E
• algoritmi lenti con risultati buoni
• algoritmi veloci con risultati cattivi
Molti algoritmi trovano pi`
u di una soluzione durante l’esecuzione, e
quindi possono fornire un risultato anche se terminati prematuramente
Definiamo δA (I , t) la differenza relativa della miglior soluzione trovata
dall’algoritmo A dopo un tempo t
• per convenzione, poniamo δA (I , t) = +∞ quando all’istante t
l’algoritmo non ha ancora trovato soluzioni ammissibili
• δA (I , t) `
e una funzione monotona non crescente di t
• quando l’algoritmo termina, δA (I , t) rimane costante
La cosa `e interessante soprattutto per algoritmi dotati di memoria o passi
casuali, dato che il loro tempo di calcolo `e fissato dall’utente
22 / 28
Classificazione
La relazione asintotica fra qualit`a del risultato e tempo di calcolo
consente di classificare gli algoritmi in
• completi: per ogni istanza I ∈ I trovano la soluzione ottima in
tempo finito
∃t¯I ∈ R+ : δA (I , t) = 0 per ogni t ≥ t¯, I ∈ I
Tipico esempio: gli algoritmi esatti
• probabilisticamente approssimativamente completi: per ogni istanza
I ∈ I, la probabilit`a che trovino la soluzione ottima tende a 1 per
t → +∞
lim Pr [δA (I , t) = 0] = 1 per ogni I ∈ I
t→+∞
Tipico esempio: molte metaeuristiche randomizzate
• essenzialmente incompleti: per alcune istanze I ∈ I, la probabilit`
a
che trovino la soluzione ottima `e strettamente < 1 per t → +∞
∃I ∈ I : lim Pr [δA (I , t) = 0] < 1
t→+∞
Tipico esempio: gli algoritmi greedy, quelli di ricerca locale, . . .
23 / 28
Generalizzazione approssimata
Un’ovvia generalizzazione sostituisce la ricerca dell’ottimo con quella di
un dato livello di approssimazione
δA (I , t) = 0 → δA (I , t) ≤ α
• algoritmi α-completi: per ogni istanza trovano una soluzione
α-approssimata in tempo finito (per es., gli algoritmi α-approssimati)
• algoritmi probabilisticamente approssimativamente α-completi: per
ogni istanza I ∈ I, la probabilit`a che trovino una soluzione
α-approssimata tende a 1 per t → +∞
• algoritmi essenzialmente α-incompleti: per alcune istanze I ∈ I, la
probabilit`a che trovino una soluzione α-approssimata `e strettamente
< 1 per t → +∞
A questo punto, possiamo tornare a vedere In come spazio degli esiti e
caratterizzare statisticamente un algoritmo in termini di compromesso fra
• l’aspetto qualitativo, descritto dalla soglia t
• l’aspetto temporale, descritto dalla soglia α
24 / 28
La probabilit`a di successo
Definiamo probabilit`a di successo πA,n (α, t) la probabilit`a che l’algoritmo
A trovi in tempo ≤ t una soluzione di livello ≤ α
πA,n (α, t) = Pr [δA (I , t) ≤ α|I ∈ In ]
Ne derivano diversi diagrammi secondari
25 / 28
Diagrammi Qualified Run Time Distribution (QRTD)
I diagrammi QRTD descrivono l’andamento del tempo necessario a
raggiungere prefissati livello di qualit`a
Sono utili quando il tempo di calcolo non `e una risorsa stringente
Se l’algoritmo `e completo, il diagramma `e lo stesso per ogni α
Se l’algoritmo `e α
¯ -approssimato, il diagramma `e lo stesso per ogni α ≥ α
¯
e coincide col diagramma RTD dell’algoritmo
26 / 28
Diagrammi Solution Quality Distribution (SQD)
I diagrammi SQD descrivono l’andamento del livello di qualit`a raggiunto
in un dato tempo di calcolo
Sono utili quando il tempo di calcolo `e una risorsa stringente
Se l’algoritmo `e α-completo, il diagramma tende per t + ∞ a un gradino
con soglia α = 0 (soluzione ottima)
Per gli algoritmi incompleti, invece, si tende a una distribuzione asintotica
27 / 28
Diagrammi Solution Quality statistics over Time (SQT)
Infine si possono tracciare le linee di livello associate ai diversi quantili
Queste descrivono il compromesso fra qualit`a e tempo di calcolo
Un algoritmo robusto avr`a linee molto ravvicinate fra loro
28 / 28
© Copyright 2025 Paperzz